Common design choices
Choosing The Right Database
- Database technology should be one of your last decisions in your initial design
- Because you may hit the “golden hammer” scenario
- The business logic should be the main factor for the architecture
- However, choosing the right storage solution always requires some consideration
- Keep in mind most functional requirements can be achieved with any database
- But at the cost of a huge performance hit
- Or at an expensive price
- Key factors:
- Structure of the data
- Query patterns
- Data volume
- Scale you need to handle
Database techniques
- Indexing
- Helper table, created from a particular column or group of columns
- Improves read queries but speed of write operations declines
- Replication
- Removes the “single point of failure” issue
- Higher complexity in terms of consistency and correctness
- Difficult to design and manage on a high scale
- Non-relational databases incorporate replication “out of the box”
- Partitioning (Sharding)
- Separates the data based on a predefined and specific rule
- Introduces complexity but it is a first-class feature in non-relational database
- Partitioning can also be used for the application logic
Caching solution
- If you have:
- Frequent database calls
- High latency independent services
- You may want to cache some data
- You may use Redis, Memcached or other technologies
- Redis is the most popular choice
- You may use Redis, Memcached or other technologies
- Caching has downsides:
- Stale data
- Overhead
- Complexity of logic
File Storage Solution
- If you store files and not structured data, you most probably do not need a database
- You use database for information which you want to query
- And files are not queried, they are delivered directly
- In such scenarios, you use blob storage
- Like Amazon S3, for example
- Blob storage allows you to store files
- And usually, for greater scale, you would use a CDN
- To reduce the latency for your geographical location
Text Search Solution
- If you want to build a search functionality, you need a search engine
- Like Elasticsearch
- In such scenarios you want to support “fuzzy search”
- Where typos are also matched, for example “airprot” search shows “airport” results
- The search engines are not databases and you do not use them as a primary one
- They guarantee fast and relevant results, not a storage solution
- Normally, you load the search engine data from another database
Time Series Solution
- Time series databases are not randomly updated like normal ones
- You add data in “append only” format
- Server metrics
- Performance monitoring
- Network data
- Sensor data
- And many more…
- They are perfect for queries which include a time period
- InfluxDB is such database
Data Warehouse Solution
- Data warehouse is used where you just put all your data in one place
- And then perform analytics over it
- It is used for offline reports and business decisions
- This solution is not used for regular everyday transactions
- It will be too slow on scale
- Hadoop is a very commonly used data warehouse solution
- But you can use other databases, if you think they will be good enough
SQL or NoSQL
- You can use a relational database, if:
- You have structured data
- You need atomicity, consistency, isolation, durability (ACID)
- Otherwise, you can use a non-relational database
- Consider Amazon products – they all have different attributes
- Then you need to consider the query pattern of your use case
- If you have vast variety of queries and attributes, you can use a NoSQL database
- You can use a wide-column database like Cassandra
- If you have small variety of attributes but huge data volume
- In this case you have huge scale of queries, but their variety is small
What about redis?
- We introduced Redis as a key-value database
- However, it is much more powerful and capable than a simple cache
- It can be used for:
- Distributed transactions
- Bounded contexts
- Asynchronous messaging
- Transactional outbox
- Telemetry
- More information explained here
What about big data?
- Big data consists of datasets which are either:
- Too large in size
- Too complex in structure
- Come to our system at a high rate
- Big data exceeds the capacity of a traditional application
- Characteristics
- Volume – terabytes per day
- Google Search, Medical health monitoring, Real-time security
- Variety – large variety of unstructured data from multiple sources
- Social media behavior
- Velocity – large scale or high frequency of events
- Online store with millions of users, Internet of Things
- Volume – terabytes per day
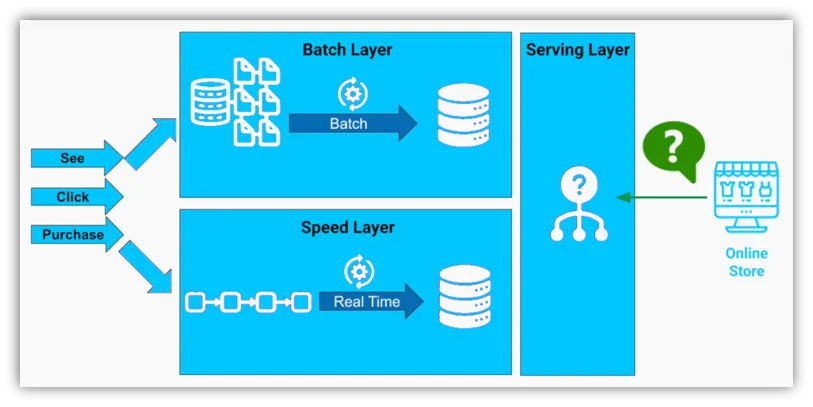
Processing big data with lambda architecture
Choosing the Initial patterns
-
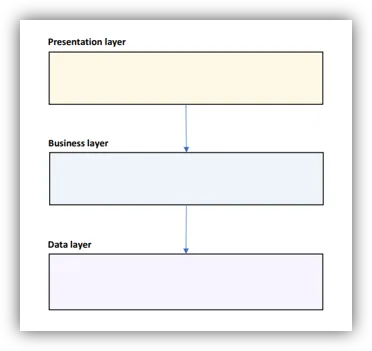
The Layered Pattern
- Good starting point
- Create 3 layers:
- UI / Presentation – visualization concerns
- Business – business logic and domain
- Data – data access layer
- If you expect a long-term project, you may choose Domain-Driven Design with Clean Architecture
- Presentation – visualization concerns
- Application – business logic
- Infrastructure – infrastructure details
- Domain – business entities
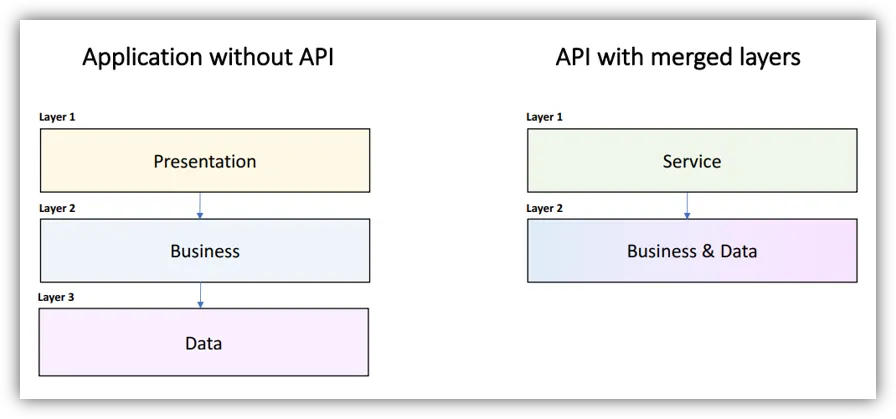
- Add a Service layer if you plan to expose an API
-
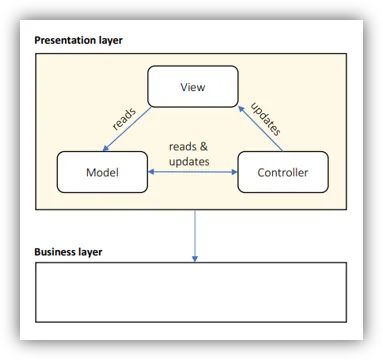
The Presentation Layer
- Use Components for:
- Containers
- Reuse
- 3rd parties
- Declarative rendering
- Like WordPress – with widgets
- Or with visual designer
- Lots of dynamic interactions
- Use MVC for lots of UI pages
- Or MVVM if the technology support data binding
- Remove this layer, if you designing an API
- Without any UI
- Without any UI
- Use Components for:
-
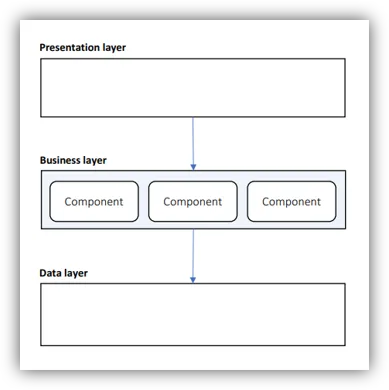
The Business Layer
- Use Components:
- Modular functionality
- Plugin support
- Business entity abstraction
- For each entity – create a component
- Declarative configuration:
- Visual workflows – like a flow chart for the business rules
- Business rules – collection of if/then/else rules
- If you don’t need the above, use an object-oriented architecture
- Use Components:
-
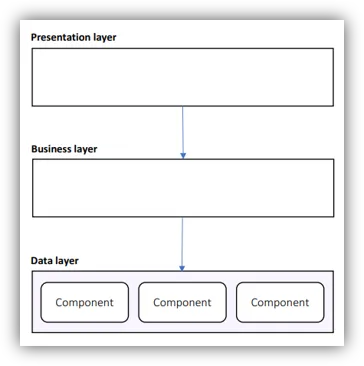
The Data Layer
- Use Components:
- Handling diverse data sources
- SQL Server, Redis, MongoDB, etc.
- Increased abstraction
- Declarative configuration
- Easily replace connection string, data storages and other mechanisms
- Handling diverse data sources
- Use Components:
-
The Service Layer
- Use Components:
- Contract management
- Containers
- Declarative configuration
- Choose Microservices if your system is composed mostly of interlocking APIs
- Never start with Microservices, unless you are completely sure
- Always choose a monolithic application with Microservices in mind
- Use Domain-Driven Design and Clean Architecture to separate contexts
- Extract microservices when necessary
- Add Message Bus if all services alter state on a common message

- Use Components:
Designing Layered Architectures
-
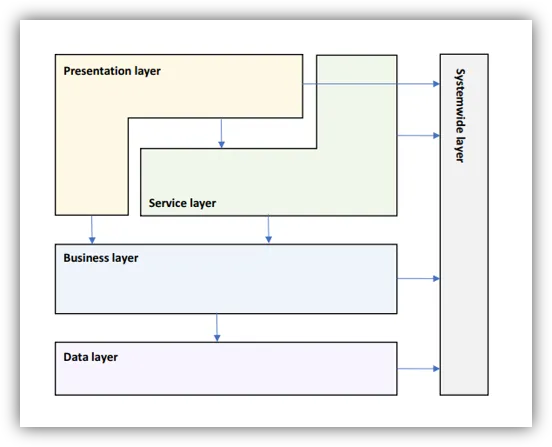
Logical Layered Design
-
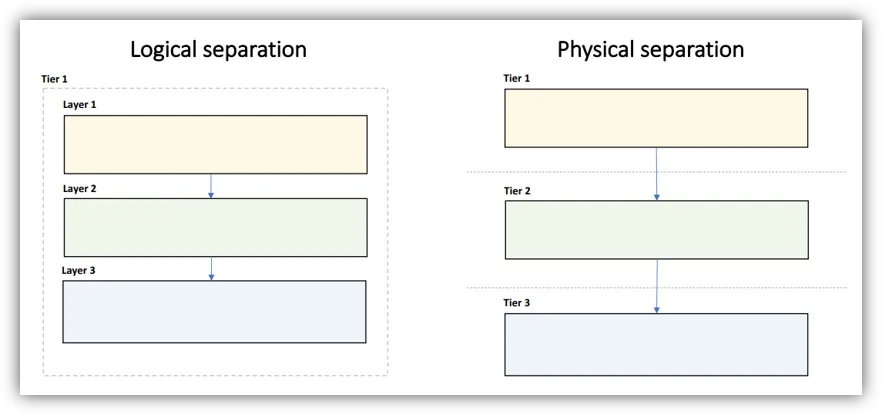
Choose Layering Strategy
-
Remove, Split & Merge Layers
-
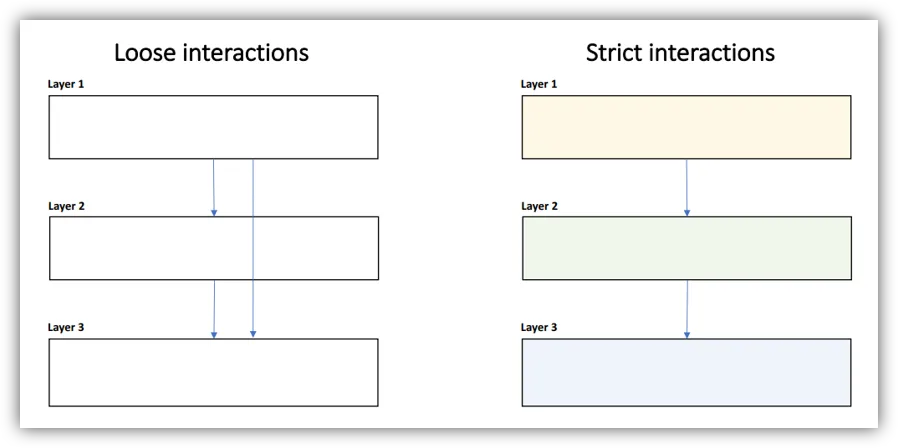
Determine Layer Interactions
-
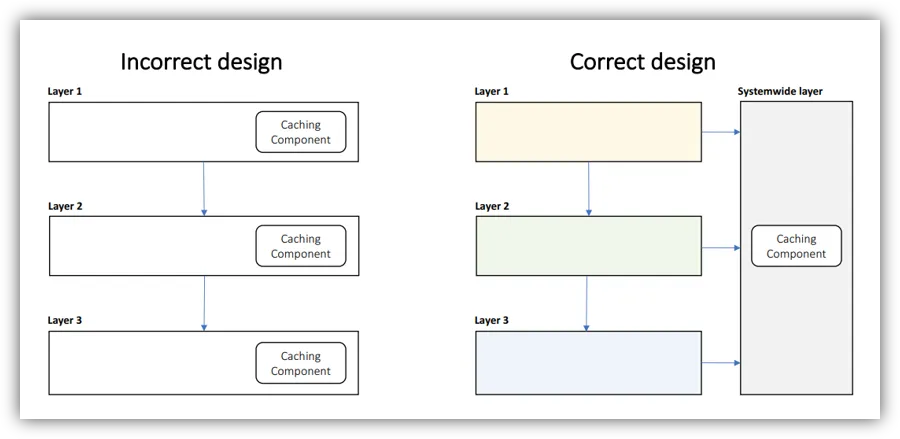
Identify System wide Concerns
-
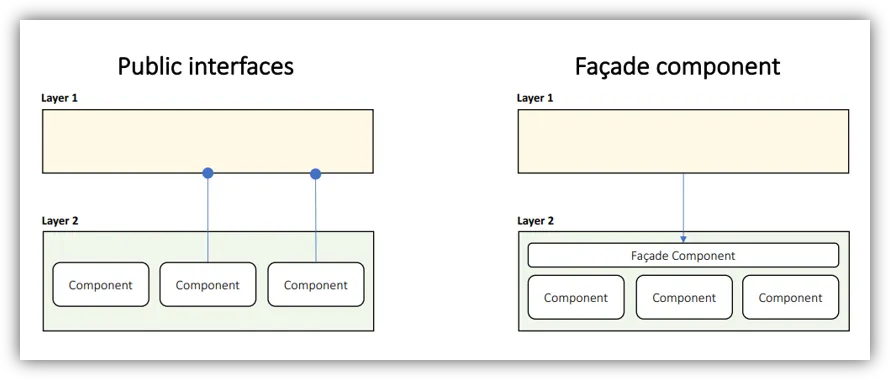
Define Layer Interfaces
Designing Low-level Components
- Always choose a set of rules to control the inevitable chaos
- SOLID is a good starting point but do not get too excited about it
- Components should be highly cohesive with clear purpose
- Components should have loose coupling and strict communication
- Components should be encapsulated with well-defined interfaces
- Define clear code style rules
- Classes, interfaces, methods, variable, constants, etc.
- Learn low-level Domain-Driven Design
- It will help you understand separation of concerns and development scalability
- And provide you with a great set of rules to achieve the above goals
Low-level Design patterns
- Design patterns are micro-architecture
- Make sure your developers are familiar with them
- Commonly useful design patterns:
- Factory – remove the “new is glue” syndrome from your code
- Repository – only if you really need it, may serve as anti-corruption layer
- Façade – hide complexity in your business logic
- Command – encapsulate actions in objects
- Strategy – supports open/close principle
Designing Service-Oriented Architectures
- Software services are self-contained modules
- They reflect the idea of describing specific logic through a well-defined interface
- Service-oriented applications are developed as independent sets
- Interacting with each other
- Using the principle of loose coupling
- Web services
- Self-describing, self-contained software module
- Available via a network
- Completes specific tasks and solves specific problems
- Can be dynamically found
- Can be accessed programmatically
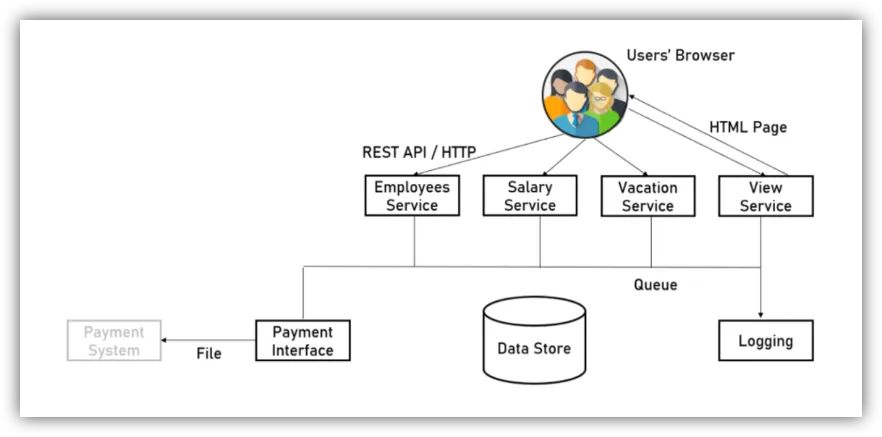
The Service Design Process
- Separate logical services
- Define data & messages
- Define service contracts
- Plan exception handling
- Define how business entities are transformed to messages
- Define how business functions are abstracted to services
Architecture styles
-
N-Tier Overview
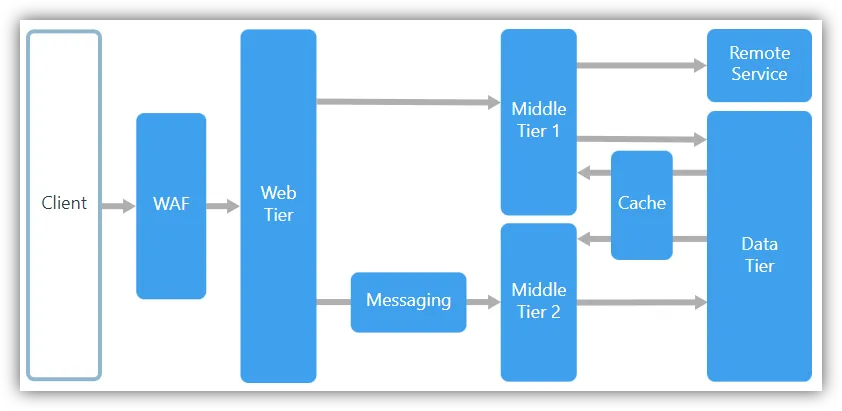
-
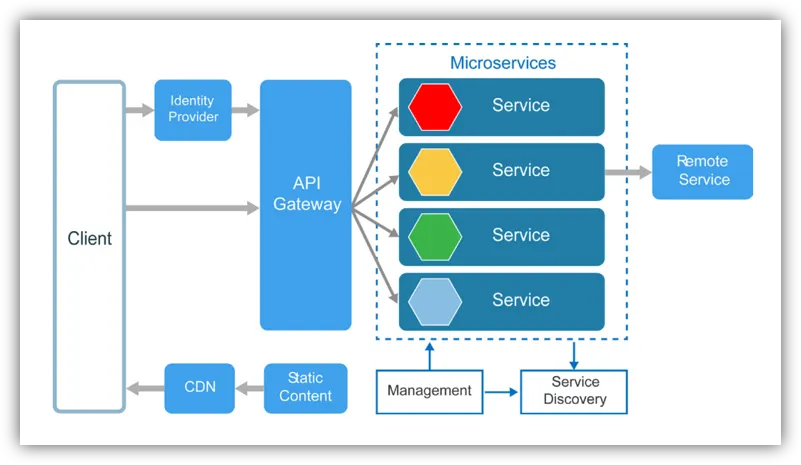
Microservices Overview